MERF: Memory-Efficient Radiance Fieldsについて
MERF: Memory-Efficient Radiance Fields
最新の3Dスキャニングと表現には、ポリゴン化せず3Dオブジェクトや空間を表現する手法として、2020年頃に発表されたNeRF (Neural Radiance Fields)や、2023年にnVidia社が公開した3DGS(Gaussian Splatting)があります。
今回はGoogleから新たに「MERF」の情報がGitHubに公開されているのを、日本語に翻訳して記録しておきたいと思います。
引用:merf: Memory-Efficient Radiance Fields for Real-time View Synthesis in Unbounded Scenes
MERF: 無制限のシーンでのリアルタイム ビュー合成のためのメモリ効率の高い放射輝度フィールド
SIGGRAPH 2023
- Christian Reiser1,2,3
- Richard Szeliski1
- Dor Verbin1
- Pratul P. Srinivasan1
- Ben Mildenhall1
- Andreas Geiger2,3
- Jonathan T. Barron1
- Peter Hedman1
- Google Research1
- Tübingen AI Center2
- University of Tübingen3
-

Paper
-

Video
-

Demos
-

Code
概要
ニューラル放射輝度フィールドにより、最先端のフォトリアリスティックなビュー合成が可能になります。ただし、既存の放射フィールド表現は、リアルタイム レンダリングするには計算負荷が高すぎるか、大規模なシーンにスケールするには多すぎるメモリを必要とします。ブラウザーで大規模なシーンのリアルタイム レンダリングを実現するメモリ効率の高い放射フィールド (MERF) 表現を紹介します。MERF は、まばらなフィーチャ グリッドと高解像度 2D フィーチャ プレーンの組み合わせを使用して、以前のまばらな体積放射輝度フィールドのメモリ消費を削減します。大規模な境界のないシーンをサポートするために、効率的なレイボックスの交差を可能にしながら、シーンの座標を境界のあるボリュームにマッピングする新しい縮小関数を導入します。体積放射輝度フィールドのフォトリアリスティックなビュー合成品質を維持しながら、リアルタイム レンダリングを実現するモデルにトレーニング中に使用されるパラメーター化をベイクするためのロスレス手順を設計します。
ビデオ
リアルタイム インタラクティブ ビューアーのデモ
実際にキャプチャされたシーン
-
-

花瓶
-

自転車
-

キッチンレゴ
-

切り株
-
-

オフィス盆栽
-

フルリビングルーム
-

キッチンカウンター
-

ツリーヒル&フラワー
表現
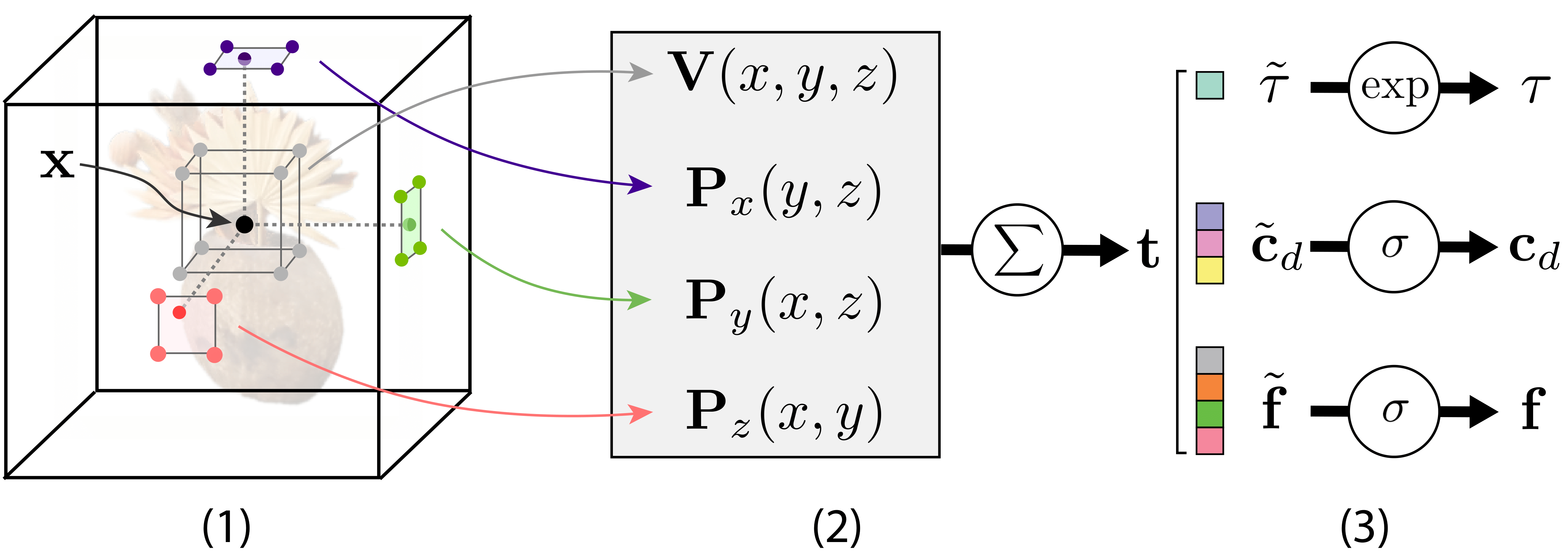
光線に沿った位置の場合: (1) 低解像度 3D グリッド上の 8 つの近傍をクエリします。そしてそれを 3 つの軸が揃った平面のそれぞれに投影し、高解像度の 2D グリッド上で各投影の 4 つの近傍をクエリします。 (2) 8 つの低解像度 3D 近傍が評価および三線形補間される一方で、4 つの高解像度 2D 近傍の 3 セットが評価および双線形補間され、結果として得られる特徴が 1 つの特徴ベクトルに合計されます。 (3) 特徴ベクトルは分割され、密度、RGB カラー、およびビュー依存効果をエンコードする特徴ベクトルの 3 つのコンポーネントに非線形にマッピングされます。
区分的射影収縮
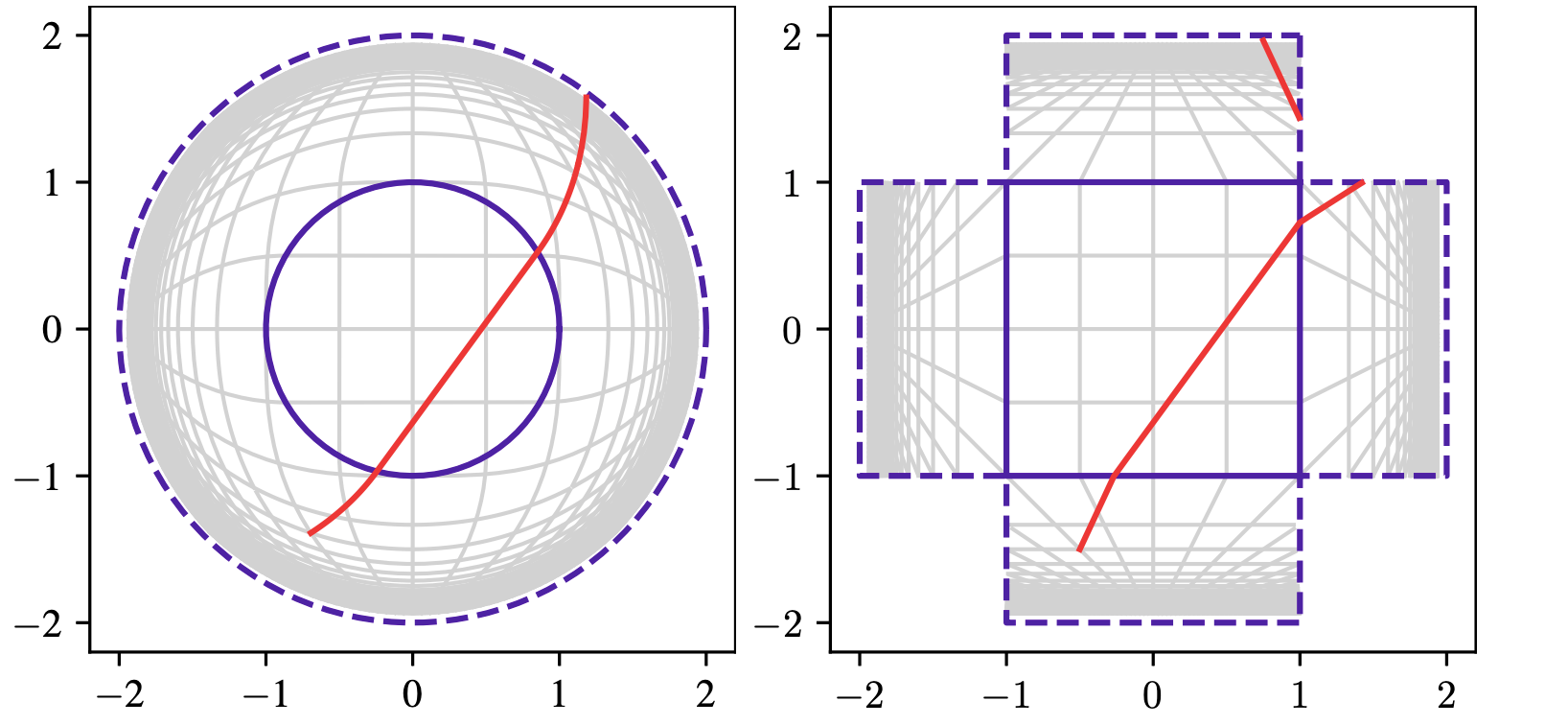
境界のないシーンをモデル化するために、縮小関数を使用します。既存の作品では、直線を曲線にマッピングする球面収縮が使用されています (左)。これにより、空のスペースをスキップするために必要な、光線と軸に合わせたバウンディング ボックス間の交差の計算が困難になります。私たちは、直線を少数のセグメントにマッピングする新しい縮小関数 (右) を提案します。交差を効率的に計算できるため、収縮関数はリアルタイム レンダリングにより適しています。
引用
@article{Reiser2023SIGGRAPH,
title={MERF: Memory-Efficient Radiance Fields for
Real-time View Synthesis in Unbounded Scenes},
author={Christian Reiser and Richard Szeliski and
Dor Verbin and Pratul P. Srinivasan and Ben Mildenhall
and Andreas Geiger and Jonathan T. Barron and Peter Hedman},
journal={SIGGRAPH},
year={2023}
}
コードの実行
- mipnerf360 データセットをダウンロードして解凍します:
curl -O http://storage.googleapis.com/gresearch/refraw360/360_v2.zip
unzip 360_v2.zip - conda を次からインストールします。 https://docs.conda.io/en/latest/miniconda.html#linux-installers
- conda 環境を作成します:
conda create --name merf python=3.9 pip - conda 環境をアクティブ化します:
conda activate merf - Python の依存環境をインストールします:
pip install -r requirements.txt - pycolmap をインストールします:
git clone https://github.com/rmbrualla/pycolmap.git ./internal/pycolmap - トレーニング、ベイク処理、評価を行い、Web ビューアと互換性のある形式にエクスポートします:
./train.sh
構築したいシーンの名前、データセットがあるパス、出力を保存するパスを./train.shで指定することができます。データセットへのパスと出力を書き込むディレクトリは./train.shで指定します。 - Web ビューアのサードパーティの依存関係をダウンロードします:
cd webviewer
mkdir -p third_party
curl https://unpkg.com/three@0.113.1/build/three.js --output third_party/three.js
curl https://unpkg.com/three@0.113.1/examples/js/controls/OrbitControls.js --output third_party/OrbitControls.js
curl https://unpkg.com/three@0.113.1/examples/js/controls/PointerLockControls.js --output third_party/PointerLockControls.js
curl https://unpkg.com/png-js@1.0.0/zlib.js --output third_party/zlib.js
curl https://unpkg.com/png-js@1.0.0/png.js --output third_party/png.js
curl https://unpkg.com/stats-js@1.0.1/build/stats.min.js --output third_party/stats.min.js - Web ビューアをローカルでホストします:
python -m http-server
シングルGPUトレーニングの調整
この論文では、16ギガバイトのVRAMを搭載したV100 GPUを8台搭載したノードですべてのモデルをトレーニングし、1シーンあたり約2時間を要した。その結果、非常に大きなバッチサイズ(2^16)を使用することができます。多くの人はシングルGPUトレーニングを好むと思いますが、シングルGPUでは、このような大きなバッチサイズはOOMエラーにつながります。私たちはデフォルトで勾配累積を有効にし(Config.gradient_accumulation_steps = 8)、シングルGPUで論文に使われたのと同じバッチサイズでトレーニングできるようにしました。メモリが16GiB未満のカードを使用している場合は、Config.gradient_accumulation_stepsを増やす必要があります。.
